




一 线程池大小
线程池的理想大小取决于被提交任务的类型以及所部署系统的特性。在代码中通常不会固定线程池的大小,而应该通过某种配置机制来提供。
要设置线程池的大小,应当避免“过大”和“过小”两种极端情况,如果线程池过大,那么大量的线程将在相对很少的CPU和内存资源上发生竞争,这不仅会导致更高的内存使用量,而且还可能耗尽资源导致系统崩溃;如果线程池过小,那么将导致很多空闲的处理器无法执行工作,从而降低了吞吐。
1.1 创建线程的开销
使用线程池很重要的一个原因,就是线程开销问题。线程在创建和使用过程中存在很大的开销:
- 关于时间,创建线程使用是直接向系统申请资源,这里会执行系统调用而导致的耗时不受JVM控制
- 关于资源,Java线程的线程栈所占用的的内存是Java堆外的,是不受Java程序控制,只受系统资源控制,默认一个线程的线程栈大小是1M(可以通过-Xss属性设置),如果每个用户请求都新建线程的话,1024个用户光线程占用都1G
- 对于操作系统来说,创建一个线程的代价是十分昂贵的,需要给它分配内存、列入调度,同时在线程切换的时候还要执行内存换页,CPU的缓存被清空,切换回来的时候重新从内存读取信息等
由于线程创建的开销,可以使用池化技术在一定程度上避免这种开销。但是线程池的大小该怎么设置,设置多大合适,后期又该怎么调整等等问题,对于这些问题,我们可以进一步做一些思考。
1.2 线程池设置大小
在设置线程池大小之前,首先要明白一点,线程池的大小设置不应该是固定的,在业务中应当做成可配置的。
那么此时有人就会有疑惑:那么在实际的业务过程中第一次使用线程池该怎么配置呢?或者面试的时候该怎么回答这个问题呢?不能说我第一次使用线程池的时候随便设置一个大小吧,有没有相关的理论支持呢?
1.2.1 线程池大小的理论支持
我翻阅过很多资料,对于线程池的大小设置可以总结为两种。
一种是《Java并发编程实战》这本书中提到的一种定义:

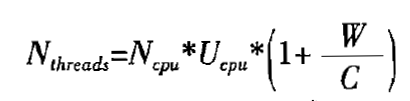
- Ncpu表示机器的CPU数量,在Java中可以使用 Runtime.getRuntime().availableProcessors() 代码获取。
- Ucpu表示CPU的使用率,值在[0,1]之间
- W/C表示阻塞时间和计算时间的比率
在上述公式中,通常CPU数我们可以直接拿到;而CPU使用率, 表示线程池能使用的CPU百分比,在理论的情况下,要使CPU使用率要达到100%的话,就可以忽略这个值;最后就是计算阻塞时间和计算时间,阻塞时间和计算时间我们可以采用一些性能分析工具或java.lang.management API来确定线程所花的时间。所以,通过这个公式,我们就可以在实际情况下估算出一个理论值出来。
理论情况下,计算为:
线程数 = CPU可用核心数 * (1 + 阻塞时间/计算时间)
另一种是《Java虚拟机并发编程》这本书提到的:
线程数 = CPU可用核心数 / (1 - 阻塞系数)
阻塞系数 = 阻塞时间 / (阻塞时间 + 计算时间)
其中阻塞系数在0和1之间。计算密集型任务的阻塞系数为0,而IO密集型的阻塞系数接近1,一个完全阻塞的任务注定是要挂掉的,所以我们无需担心阻塞系数为1。
而阻塞时间和计算时间在上文中我们已经提到是可以计算出来的,最终通过这个公式也可以计算出来。
1.2.2 线程池大小设置示例
有了上述的理论支持,我们可以先看一组示例:
例如,在一个请求中,计算操作需要 5ms,IO(文件IO或请求其他接口的网络IO)操作需要 100ms,对于一台4个CPU的服务器而言,在理论情况下(即其他资源都能发挥最大),应该设置多大的线程数?
对于上述的问题,我们可以通过上文中的理论进行计算,例如我们使用第一组公式计算:
- 首先这个操作是一个计算和IO混合的操作,计算出 W/C的结果是:100 / 5 = 20
- CPU核心数为4, 最后得出结果:4 * (1 + 20) = 84
而使用第二组公式计算:
- 已知阻塞时间和计算时间,可以计算出 阻塞系数 = 100 / (100 + 5) = 20/21
- CPU核心数为4, 最后得出结果:4 / (1 - 20/21) = 84
可见两组计算的结果都是一致的。
而对于上述的案例,我们接着往下深入:
例如,在一个请求中,计算操作需要 5ms,DB操作需要 100ms,而DB的QPS上限是1000,在其他资源充足的情况下,那么此时线程池又该设置多大合适呢?
这里增加了QPS(每秒查询率)的指标
- 单个线程操作时间是105ms,那么我们可以得出单个线程QPS:1000 / 105 = 200/21
- 如果现在DB的QPS上限为1000,而每个线程的QPS是 200/21,那么我们可以得出线程数为:1000 / (200/21) = 105
这一个示例是在CPU、内存等资源充足的情况下的理论值,如果这个示例再加上可用CPU为4个的话,其实线程数并不能设置为105,因为最理想的情况下线程数为84,如果强制设置为105的话,那么会有一部分线程因为CPU资源不足而导致无法调度,如果强制添加反而会增加线程切换的损耗,最终导致吞吐量反而是下降的。此时如果为84是不管QPS等条件的,所以即时QPS上限为1000,也不应该设置为105, 而是设置为84。
1.2.3 线程池大小设置的指标及目标
有了理论支持以及上述的几个示例,下面我们思考线程池大小设置的指标是什么?
对于很多人来说,线程池设置大小的指标并没有概念,更不知设置线程池大小的依据是什么。首先我们知道线程池不可能无限设置大小,在很多资料中都提到了一种通用的设计,计算密集型的大小可以N(N表示CPU数量),IO密集型的大小可以设置为2N,其实这种设计本质上是没有问题的。我们可以试想,在计算密集型中,因为计算耗时本身就小,所以设置CPU核心数,这样才不会导致线程切换、内核调度、清空CPU(一级、二级、三级)缓存、重新载入CPU缓存而导致的损耗;而在IO密集型中,相对计算密集型的业务,IO密集型的阻塞时间要更长,由于线程被阻塞了,那么CPU的空闲时间就出来了,这样就可以增加更多的线程用于CPU调度从而提高吞吐了,但是这种数量不可能无限制增加,2N通常来说也是一个经验值,只是通用的一种设计。所以才有了上述的这种通用设计。
说白了,线程池的大小设置就是为了使CPU的利用率更高,以致达到最高,即为了更高的吞吐量。
当然,我们可以对线程池大小设置的指标进行总结:
- 计算耗时
- IO操作耗时
- 内存资源
- 硬盘资源
- 网络带宽资源
- 数据库连接资源
- 服务器的成本
1.2.4 动态调整参数
通过 9、Executor及ThreadPoolExecutor源码解析 这一章的学习,我们知道JDK中的标准线程池是可以对参数进行重新赋值的:
- setCorePoolSize(int):设置核心大小
- setKeepAliveTime(long, TimeUnit):设置线程存活时间
- setMaximumPoolSize(int):设置线程池最大大小
- setRejectedExecutionHandler(RejectedExecutionHandler):设置拒绝处理器
- setThreadFactory(ThreadFactory):设置线程创建工厂
线程池的大小设置本身就不是设置一次而一劳永逸的,因为随着机器的资源不同(如CPU资源、内存资源)、业务本身的灵活性(后期对线程业务的变更)等情况需要重新调整线程池的大小。所以线程池的大小应当是做成可配置的,并且根据系统的监控做一步一步调整的,当有配置的变化的时候应该使用setXX(XX)变更。
但是JDK的标准线程池ThreadPoolExecutor并没有阻塞队列重新设置大小的API,那么怎么调整阻塞队列的大小呢,我们往下看。
二 阻塞队列的大小重置
ThreadPoolExecutor没有为我们提供阻塞队列的重置的功能,并且在原生的阻塞队列(如ArrayBlockingQueue、LinkedBlockingQueue等)也并没有对大小的变更的API,他们内部的队列大小的参数都是final的修饰,所以在以下情况我们是需要调整阻塞队列大小的:
- 由于其他的业务原因,导致系统需要增加内存数,增加内存后,阻塞队列的容量理论上是可以进行提升的,这样可以提升ThreadPoolExecutor本身的处理能力
- 由于用户量降低等原因,从而降低内存数,降低内存后,理应对阻塞队列进行缩容,避免内存溢出导致系统问题
针对上述情况,我们可以对阻塞队列的大小重置也进行设计。此时有些人会说,将阻塞队列大小重新配置后重启机器不就解决了吗?这种当然可以解决,但是在一定程度上要暂停业务或因停止机器而临时性出现吞吐降低,这种并不是我们想要的效果,我们的目的是与ThreadPoolExecutor其他的参数一样,通过setXX(XX)在不停机的情况下变更线程池的阻塞队列大小。
2.1 设计思维
一个可扩缩容的阻塞队列,面临如下一些情况:
- 有足够的空间存储旧的数据:
- 新的容量较旧的容量大
- 新的容量较旧的容量小,但是较当前队列中存在的元素的数量要大或者相等
- 数据移动完成之后,如果新的容量还有剩余,并且有写线程在等待的情况,则需要唤醒写线程
- 没有足够的空间存储旧的数据:
- 新的容量较当前队列中存在的元素的数量要小
- 需要解决怎么提取多余的元素,如提取最早的元素、提取最新的元素、随机提取等
- 提取出多余的元素后又该怎么处理,比如丢弃处理、记录日志等
针对上述的情况,我们就可以设计出一个可扩缩容的阻塞队列,并针对不同的情况,允许用户可自行定义:
- RescalableBlockingQueue:顶层接口,定义了扩缩容的方法,提取器操作等。具体的实现可根据业务自行设计数据结构及算法
- Extracter:提取器,即没有足够空间存储旧的数据的时候,怎么提取多余的数据。比如可提取最早的元素、最近的元素、随机提取等。提取之后交由回收器进行回收
- AbstractExtracter:抽象的提取器,可进行简单的重复工作的上层实现,核心的提取工作交由子类提取
- ArrayAbstractExtracter:底层以数组的数据结构实现队列的提取器
- LinkedAbstractExtracter:底层以链表的数据结构实现队列的提取器
- Recycler:回收器,即Extracter提取出多余的数据之后,回收器进行回收
- AbstractRecycler:回收器的一些基本实现
- DefaultRecycler:默认的实现,什么都不做直接丢弃
- ThreadPoolRejectedRecycler:针对线程池的一种实现,使用线程池的拒绝处理器处理剩余的数据
上述三大组件,用户可根据接口、抽象类等自行实现自己的逻辑,一些默认实现的方式可供参考。
2.2 RescalableBlockingQueue
RescalableBlockingQueue,顶层的扩缩容队列的接口,代码如下
/**
* 可重置大小的阻塞队列
*/
public interface RescalableBlockingQueue<E> extends BlockingQueue<E> {
/**
* 重新缩放阻塞队列大小。如果新的容量与旧的容量相等则不做操作
* @param capacity 新的大小
* @return this
*/
RescalableBlockingQueue<E> rescaleCapacity(int capacity) throws InterruptedException;
/**
* 获取截取器
* @return Extracter
*/
<R, V> Extracter<R, E, V> getExtracter();
/**
* 设置截取器
* @param extracter 截取器
*/
<R, V> void setExtracter(Extracter<R, E, V> extracter);
/**
* 获取回收器
* @return 回收器
*/
Recycler<E> getRecycler();
/**
* 设置回收器
* @param recycler 回收器
*/
void setRecycler(Recycler<E> recycler);
}
RescalableBlockingQueue继承了BlockingQueue接口,所以有阻塞队列的全部功能。其次定义了 rescaleCapacity(int) 方法实现队列的重新缩放;get/set extracter表示对提取器操作。
具体逻辑交由子类控制。我这里实现了一种方式,使用数组的数据结构实现的可扩缩容的阻塞队列:ArrayRescalableBlockingQueue。而如果想要实现自己的,则实现RescalableBlockingQueue接口即可。
2.2.1 ArrayRescalableBlockingQueue
底层以数组实现的可扩缩容的阻塞队列,当然,我这里的功能去除了迭代器的功能(也就是没有foreach等循环功能),因为我这篇文章不是介绍迭代器的原理的,如果有兴趣或者生产使用建议参考ArrayBlockingQueue的迭代器设计。ArrayRescalableBlockingQueue全部代码如下:
public class ArrayRescalableBlockingQueue<E> extends AbstractQueue<E> implements RescalableBlockingQueue<E>, Serializable {
private static final long serialVersionUID = -7472650554348764120L;
/** 保存的元素 */
private Object[] items;
/** 容量大小 */
private int capacity;
/** 当前队列的元素个数 */
private int count;
/** 存放元素时的指针 */
private int putIndex;
/** 获取元素时的指针 */
private int takeIndex;
/** 锁 */
private final ReentrantLock mainLock;
/** 空时的条件队列 */
private final Condition notEmptyCondition;
/** 满的时候条件队列 */
private final Condition notFullCondition;
/** 截取器 */
private ArrayAbstractExtracter<E> extracter;
/**
* 构造函数
* @param capacity 容量
*/
public ArrayRescalableBlockingQueue(int capacity) {
this(capacity, false);
}
/**
* 构造函数
* @param capacity 容量
* @param fair 是否公平锁
*/
public ArrayRescalableBlockingQueue(int capacity, boolean fair) {
this(capacity, fair, new ArrayOldestExtracter<>());
}
/**
* 构造函数
* @param capacity 容量
* @param fair 是否公平锁
*/
public ArrayRescalableBlockingQueue(int capacity, boolean fair, ArrayAbstractExtracter<E> extracter) {
//参数校验 Start
if (capacity <= 0) {
throw new IllegalArgumentException();
}
if (extracter == null) {
throw new NullPointerException();
}
//参数校验 End
this.capacity = capacity;
this.items = new Object[capacity];
this.mainLock = new ReentrantLock(fair);
notEmptyCondition = this.mainLock.newCondition();
this.notFullCondition = this.mainLock.newCondition();
this.extracter = extracter;
}
/**
* 重新缩放阻塞队列大小。如果新的容量与旧的容量相等则不做操作
* @param capacity 新的大小
* @return this
*/
@Override
public RescalableBlockingQueue<E> rescaleCapacity(int capacity) throws InterruptedException {
//校验 Start
if (capacity <= 0) {
throw new IllegalArgumentException();
}
//校验 End
final ReentrantLock lock = this.mainLock;
lock.lockInterruptibly();
try {
final int oldCapacity = this.capacity;
//容量相同, 不做变更 Start
if (capacity == oldCapacity) {
return this;
}
//容量相同, 不做变更 End
//没有元素 Start
if (count == 0) {
this.items = new Object[capacity];
this.capacity = capacity;
this.takeIndex = this.putIndex = 0;//clear()方法会保持到putIndex, 避免越界问题重置指针
return this;
}
//没有元素 End
final Object[] items = this.items;
if (capacity < count) {//没有足够的空间存放以前的数据
final ArrayExtractTuple extract = extracter.extract(createExtractTuple(capacity));//处理
//数组移动完成, 重置相关指针 Start
this.takeIndex = 0;
this.putIndex = extract.getPutIndex();
this.capacity = capacity;
this.count = extract.getCount();
this.items = extract.getItems();
//数组移动完成, 重置相关指针 End
} else {//有足够的空间存放以前的数据(新的容量大于旧的容量或者新的容量大于等于当前数组有效数据的数量), 移动数组
Object[] newItems = new Object[capacity];
int takeIndex = this.takeIndex;
final int putIndex = this.putIndex;
int index = 0;
do {
final Object item = items[takeIndex];
items[takeIndex] = null;//help gc
newItems[index] = item;
index++;
if (++takeIndex == oldCapacity) {
takeIndex = 0;
}
} while (takeIndex != putIndex);
//数组移动完成, 重置相关指针 Start
this.items = newItems;
this.capacity = capacity;
this.putIndex = index == capacity ? 0 : index;
this.takeIndex = 0;
//数组移动完成, 重置相关指针 End
//如果有足够空间则激活写线程 Start
int i = this.capacity - count;
for (; i > 0 && lock.hasWaiters(notFullCondition); i--) {
notFullCondition.signal();
}
//如果有足够空间则激活写线程 End
}
return this;
} finally {
lock.unlock();
}
}
/**
* 获取队列大小
* @return 队列大小
*/
@Override
public int size() {
final ReentrantLock lock = this.mainLock;
try {
lock.lock();
return count;
} finally {
lock.unlock();
}
}
/**
* 添加一个元素到队列中, 如果队列已经满了, 则等待, 直到队列中有位置添加
* @param e 元素
* @throws InterruptedException 异常
*/
@Override
public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.mainLock;
lock.lockInterruptibly();
try {
//队列已满, 则当前线程等待 Start
while (count == capacity) {
notFullCondition.await();
}
//队列已满, 则当前线程等待 End
enqueue(e);//元素入队, 并唤醒获取线程
} finally {
lock.unlock();
}
}
/**
* 添加一个元素到队列中, 如果队列已经满了, 则等待timeout时间后如果还没有空间的话则返回false
* @param e 元素
* @param timeout 如果队列满了等待的超时时间
* @param unit 时间单位
* @return 是否添加成功
* @throws InterruptedException 异常
*/
@Override
public boolean offer(E e, long timeout, TimeUnit unit) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.mainLock;
long nanos = unit.toNanos(timeout);
lock.lockInterruptibly();
try {
//队列已满, 等待 Start
while (count == capacity) {
//超时了 Start
if (nanos <= 0) {
return false;
}
//超时了 End
nanos = notFullCondition.awaitNanos(nanos);
}
//队列已满, 等待 End
enqueue(e);
return true;
} finally {
lock.unlock();
}
}
/**
* 添加一个元素到队列中, 如果队列已经满了, 则直接返回false
* @param e 元素
* @return 是否添加成功
*/
@Override
public boolean offer(E e) {
final ReentrantLock lock = this.mainLock;
lock.lock();
try {
//队列已满 Start
if (count == capacity) {
return false;
}
//队列已满 End
enqueue(e);
return true;
} finally {
lock.unlock();
}
}
/**
* 从队列中获取元素。如果队列为空的话, 那么等待, 直到队列中有元素
* @return 元素
* @throws InterruptedException 异常
*/
@Override
public E take() throws InterruptedException {
final ReentrantLock lock = this.mainLock;
lock.lockInterruptibly();
try {
//队列没有元素 Start
while (count == 0) {
notEmptyCondition.await();
}
//队列没有元素 End
return dequeue();
} finally {
lock.unlock();
}
}
/**
* 从队列中获取元素, 如果队列为空的话, 那么等待timeout时间后还是为空的话则返回null
* @param timeout 超时时间
* @param unit 时间单位
* @return 元素
* @throws InterruptedException 异常
*/
@Override
public E poll(long timeout, TimeUnit unit) throws InterruptedException {
final ReentrantLock lock = this.mainLock;
long nanos = unit.toNanos(timeout);
lock.lockInterruptibly();
try {
//队列没有元素 Start
while (count == 0) {
//超时了 Start
if (nanos <= 0) {
return null;
}
//超时了 End
nanos = notEmptyCondition.awaitNanos(nanos);
}
//队列没有元素 End
return dequeue();
} finally {
lock.unlock();
}
}
/**
* 获取一个元素。如果当前队列是空的则返回null。同时会唤醒添加操作的条件队列的头节点
* @return 元素
*/
@Override
public E poll() {
final ReentrantLock lock = this.mainLock;
lock.lock();
try {
return count == 0 ? null : dequeue();
} finally {
lock.unlock();
}
}
/**
* 获取元素。只是加锁后获取元素, 不做其他操作
* @return 元素
*/
@Override
public E peek() {
final ReentrantLock lock = this.mainLock;
lock.lock();
try {
return itemAt(takeIndex);
} finally {
lock.unlock();
}
}
/**
* 获取队列剩余空间
* @return 剩余空间
*/
@Override
public int remainingCapacity() {
final ReentrantLock lock = this.mainLock;
lock.lock();
try {
return capacity - count;
} finally {
lock.unlock();
}
}
/**
* 将队列中的元素全部放到指定的集合中
* @param c 集合
* @return 放入集合的元素数量
*/
@Override
public int drainTo(Collection<? super E> c) {
return drainTo(c, Integer.MAX_VALUE);
}
/**
* 将队列中的元素全部放到指定的集合中
* @param c 集合
* @param maxElements 放入多少个元素
* @return 放入集合的元素数量
*/
@Override
public int drainTo(Collection<? super E> c, int maxElements) {
//参数校验 Start
checkNotNull(c);
if (c == this) {
throw new IllegalArgumentException();
}
if (maxElements <= 0) {
return 0;
}
//参数校验 End
final Object[] items = this.items;
final ReentrantLock lock = this.mainLock;
lock.lock();
try {
final int min = Math.min(maxElements, count);
int i = 0;
int take = takeIndex;
try {
while (i < min) {
@SuppressWarnings("unchecked")
final E item = (E) items[take];
c.add(item);
items[take] = null;//回收垃圾
if (++take == capacity) {
take = 0;
}
i++;
}
return min;
} finally {
if (i > 0) {
count -= i;
takeIndex = take;
//因为上述删除了元素, 所以这里可以唤醒put操作的线程了 Start
for (; i > 0 && lock.hasWaiters(notFullCondition); i--) {
notFullCondition.signal();
}
//因为上述删除了元素, 所以这里可以唤醒put操作的线程了 End
}
}
} finally {
lock.unlock();
}
}
/**
* 清空队列元素
*/
@Override
public void clear() {
final Object[] items = this.items;
final ReentrantLock lock = this.mainLock;
lock.lock();
try {
int j = count;
//队列没有元素 Start
if (j <= 0) {
return;
}
//队列没有元素 End
//清空元素 Start
int i = takeIndex;
do {
items[i] = null;
if (++i == capacity) {
i = 0;
}
} while (i != putIndex);
takeIndex = putIndex;
count = 0;
//清空元素 End
//可以唤醒写线程了 Start
for (; j > 0 && lock.hasWaiters(notFullCondition); j--) {
notFullCondition.signal();
}
//可以唤醒写线程了 End
} finally {
lock.unlock();
}
}
/**
* 是否包含指定的元素
* @param o 元素
* @return true/false
*/
@Override
public boolean contains(Object o) {
if (o == null) {
return false;
}
final Object[] items = this.items;
final ReentrantLock lock = this.mainLock;
lock.lock();
try {
//队列没有元素 Start
if (count <= 0) {
return false;
}
//队列没有元素 End
int i = takeIndex;
final int putIndex = this.putIndex;
do {
//找到 Start
if (o.equals(items[i])) {
return true;
}
//找到 End
if (++i == capacity) {
i = 0;
}
} while (i != putIndex);
return false;//没有找到
} finally {
lock.unlock();
}
}
/**
* 删除指定的元素, 这个方法可能会移动数组, 效率不高
* @param o 指定的元素
* @return true/false
*/
@Override
public boolean remove(Object o) {
if (o == null) {
return false;
}
final Object[] items = this.items;
final ReentrantLock lock = this.mainLock;
lock.lock();
try {
//队列没有元素 Start
if (count <= 0) {
return false;
}
//队列没有元素 End
final int putIndex = this.putIndex;//写指针
int i = takeIndex;//读指针
do {
//找到 Start
if (o.equals(items[i])) {
removeAt(i);//移除并移动数组
return true;
}
//找到 End
if (++i == capacity) {
i = 0;
}
} while (i != putIndex);
return false;//没有找到
} finally {
lock.unlock();
}
}
/**
* 不支持的功能
*/
@Override
public Iterator<E> iterator() {
throw new IteratorException();
}
/**
* 获取指定位置元素
* @param index 指定位置
* @return 元素
*/
@SuppressWarnings("unchecked")
final E itemAt(int index) {
return (E)items[index];
}
/**
* 移除并移动数组, 这里的removeIndex位置需要上层保证肯定有元素
* @param removeIndex 要删除的索引
*/
private void removeAt(int removeIndex) {
final Object[] items = this.items;//数组
if (removeIndex == takeIndex) {//移除队首, 不需要移动数组
items[takeIndex] = null;
if (++takeIndex == capacity) {//已经到了容量大小了
takeIndex = 0;
}
} else {//不是当前读指针处, 那么需要移动数组
final int putIndex = this.putIndex;
for (int i = removeIndex;;) {
int next = i + 1;//下一个元素
if (next == capacity) {
next = 0;
}
//移动元素 Start
if (next != putIndex) {
items[i] = items[next];
i = next;
continue;
}
//移动元素 End
//已经移动完成了 Start
items[i] = null;
this.putIndex = i;
break;
//已经移动完成了 End
}
}
count--;
notFullCondition.signal();//移除元素了, 写线程可以被唤醒了
}
/**
* 转换成数组
* @return 数组
*/
@Override
public Object[] toArray() {
Object[] a;
final ReentrantLock lock = this.mainLock;
lock.lock();
try {
final int count = this.count;
a = new Object[count];
int n = items.length - takeIndex;
if (count <= n)
System.arraycopy(items, takeIndex, a, 0, count);
else {
System.arraycopy(items, takeIndex, a, 0, n);
System.arraycopy(items, 0, a, n, count - n);
}
} finally {
lock.unlock();
}
return a;
}
/**
* 将元素添加到队列中, 这里线程不安全, 所以需要在有锁的情况下调用该方法。
* 同时会唤醒{@link #notEmptyCondition} 条件队列
* @param e 元素
*/
private void enqueue(E e) {
final Object[] items = this.items;
items[putIndex] = e;
if (++putIndex == capacity) {//如果下一次的putIndex到了容量, 那么就从0开始
putIndex = 0;
}
count++;
notEmptyCondition.signal();
}
/**
* 将元素从阻塞队列中移去并返回。同时会唤醒 {@link #notFullCondition} 条件队列
*/
private E dequeue() {
final Object[] items = this.items;
@SuppressWarnings("unchecked")
final E item = (E)items[takeIndex];//获取元素
items[takeIndex] = null;//回收垃圾
if (++takeIndex == capacity) {//如果下一次的takeIndex到了容量, 那么就从0开始
takeIndex = 0;
}
count--;
notFullCondition.signal();
return item;
}
private static void checkNotNull(Object e) {
if (e == null) {
throw new NullPointerException();
}
}
private ArrayExtractTuple createExtractTuple(int newCapacity) {
return new ArrayExtractTuple(items, newCapacity, capacity, count, putIndex, takeIndex);
}
@Override
@SuppressWarnings("unchecked")
public ArrayAbstractExtracter<E> getExtracter() {
return this.extracter;
}
@Override
public <R, V> void setExtracter(Extracter<R, E, V> extracter) {
if (extracter instanceof ArrayAbstractExtracter) {
throw new IllegalArgumentException();
}
this.extracter = (ArrayAbstractExtracter<E>) extracter;
}
@Override
public Recycler<E> getRecycler() {
return extracter.getRecycler();
}
@Override
public void setRecycler(Recycler<E> recycler) {
extracter.setRecycler(recycler);
}
}
主体的功能与ArrayBlockingQueue一样,没有实现迭代器的功能。当然,如果要实现迭代器的功能的话,可参考ArrayBlockingQueue,需要解决的就是在扩缩容的时候,迭代器相关的指针(如cursor游标、nextIndex下一个元素的指针)操作(如重置等);也可设计成类似ArrayList那样,如果数组移动了,则抛出异常,这种设计要简单很多。
我这里实现的ArrayRescalableBlockingQueue的 rescaleCapacity(int) 的逻辑流程如下:
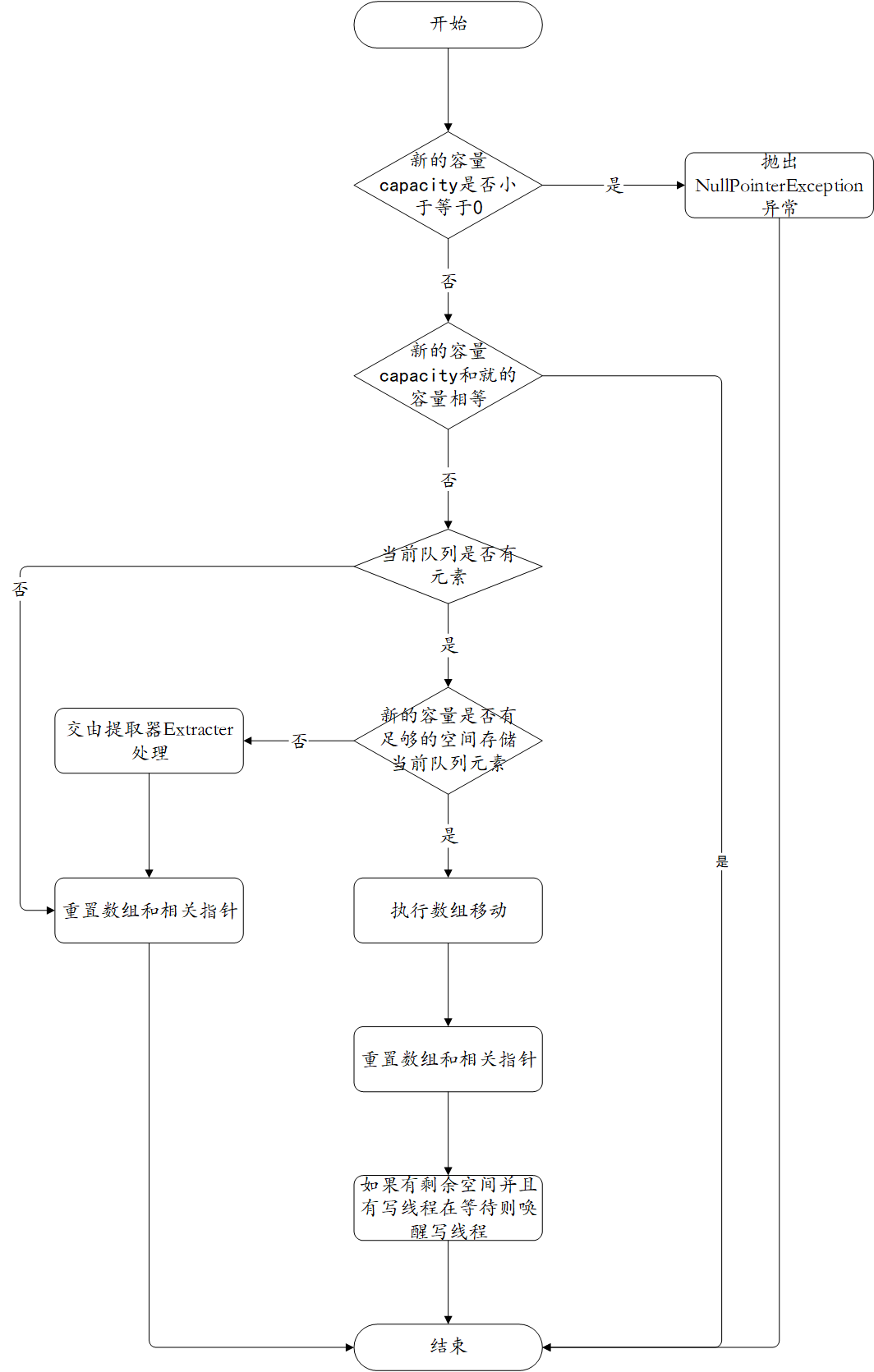
通过上述流程图就很容易理解重置容量的原理了,当有足够的空间存储当前队列的数据的时候,其实就是普通的数组移动,很好理解;但是当新的容量没有足够的空间存放当前队列的数据的时候,就需要特殊处理了,即会将实时的数据交由Extracter处理,然后得到结果后重新对相关的指针和数组赋值,这种情况的主体逻辑在Extracter中。
2.3 Extracter提取器
Extracter设计的目的是为了让用户可自行扩展怎么提取多余的数据、怎么处理多余的数据。Extracter接口的代码如下:
/**
* 当可缩放的阻塞队列{@link RescalableBlockingQueue}进行缩放时, 当缩容的时候, 怎么截取多出的数据, 使用该提取器处理
*/
public interface Extracter<R, E, V> {
/**
* 处理, 返回的结果即截取完成后的结果, 使用方可直接使用的数据
* @return 结果
*/
R extract(V v);
/**
* 获取回收器
* @return 回收器
*/
Recycler<E> getRecycler();
/**
* 设置回收器
* @param recycler 回收器
*/
void setRecycler(Recycler<E> recycler);
}
使用 extract(V) 方法处理,返回的类型R就是处理后的数据,对于RescalableBlockingQueue来说就是队列和相关指针数据。get/set recycler 是对回收器的操作。
AbstractExtracter是Extracter的基本实现,代码如下:
/**
* 抽象的提取器, 这里提取完成之后会调用{@link Recycler#recycle(Collection)}处理
* @param <R> 返回结果
* @param <E> 用于存放到阻塞队列的元素类型
* @param <V> 输入值
*/
public abstract class AbstractExtracter<R, E, V extends BaseExtractTuple> implements Extracter<R, E, V> {
public static final Recycler<Void> DEFAULT = new DefaultRecycler();
/** 回收器 */
protected Recycler<E> recycler;
@SuppressWarnings("unchecked")
protected AbstractExtracter() {
this((Recycler<E>) DEFAULT);
}
protected AbstractExtracter(Recycler<E> recycler) {
setRecycler(recycler);
}
@Override
public Recycler<E> getRecycler() {
return recycler;
}
@Override
public void setRecycler(Recycler<E> recycler) {
if (recycler == null) {
throw new NullPointerException();
}
this.recycler = recycler;
}
@Override
public R extract(BaseExtractTuple extractTuple) {
//这里是缩容处理, 不应该存在新的队列容量超过当前队列元素的数量的情况 Start
if (extractTuple.getNewCapacity() > extractTuple.getCount()) {
throw new ExtractException();
}
//这里是缩容处理, 不应该存在新的队列容量超过当前队列元素的数量的情况 End
final Collection<E> reclaims = recycler.createCollection(extractTuple.getCount() - extractTuple.getNewCapacity());
@SuppressWarnings("unchecked")
final R r = doExtract(reclaims, (V)extractTuple);//提取处理
doRecycle(reclaims);//回收处理, 不影响主流程
return r;
}
/**
* 提取处理
* @param reclaims 多余的数据存放的集合
* @param v v
* @return R
*/
protected abstract R doExtract(Collection<E> reclaims, V v);
/**
* 做回收处理, 这里不会影响主流程, 不会抛异常
* @param reclaims 待回收的集合
*/
private void doRecycle(Collection<E> reclaims) {
try {
recycler.recycle(reclaims);
} catch (Throwable cause) {
//ignore
}
}
/**
* 取回操作
* @param reclaims 集合
* @param item 待取回的元素
* @param isRetrieved 是否需要取回
*/
@SuppressWarnings("unchecked")
protected void addCollection(Collection<E> reclaims, Object item, final boolean isRetrieved) {
if (isRetrieved) {
reclaims.add((E)item);
}
}
/**
* 默认的回收器, 什么也不做
*/
public static class DefaultRecycler implements Recycler<Void> {
@Override
public void recycle(Collection<Void> pendings) {
}
@Override
public Collection<Void> createCollection(int size) {
return null;
}
}
}
AbstractExtracter有一个默认的回收器DefaultRecycler,表示什么都不做。并且对 extract(V) 方法做了实现,最终的核心逻辑委托给了抽象函数 doExtract(Collection, V),子类覆写这个方法即可实现。最后将多余的数据交给了方法doRecycler(Collection) 处理,这个方法主要就是使用Recycler处理多余的数据,但是不会抛出异常,因为程序走到这里的时候应当不被打断的。
注意,这里的V是BaseExtractTuple ,BaseExtractTuple承载了数据载体的作用,因为经过Extracter处理的时候需要一些实时的数据,BaseExtractTuple的代码如下:
public class BaseExtractTuple {
/** 新的队列容量 */
private int newCapacity;
/** 旧的队列容量 */
private int oldCapacity;
/** 当前队列的元素数量 */
private int count;
public BaseExtractTuple() {
}
public BaseExtractTuple(int newCapacity, int oldCapacity, int count) {
this.newCapacity = newCapacity;
this.oldCapacity = oldCapacity;
this.count = count;
}
public int getNewCapacity() {
return newCapacity;
}
public BaseExtractTuple setNewCapacity(int newCapacity) {
this.newCapacity = newCapacity;
return this;
}
public int getOldCapacity() {
return oldCapacity;
}
public BaseExtractTuple setOldCapacity(int oldCapacity) {
this.oldCapacity = oldCapacity;
return this;
}
public int getCount() {
return count;
}
public BaseExtractTuple setCount(int count) {
this.count = count;
return this;
}
}
2.3.1 ArrayAbstractExtracter
ArrayAbstractExtracter是以数组的数据结构的提取器,其代码如下:
public abstract class ArrayAbstractExtracter<E> extends AbstractExtracter<ArrayExtractTuple, E, ArrayExtractTuple> {
public ArrayAbstractExtracter() {
super();
}
public ArrayAbstractExtracter(Recycler<E> recycler) {
super(recycler);
}
}
ArrayAbstractExtracter的类型V和类型R都是ArrayExtractTuple,作为数组的载体,里面存放的是数组和相关指针,其代码如下:
public class ArrayExtractTuple extends BaseExtractTuple {
/** 当前队列 */
private Object[] items;
/** 存放元素时的指针 */
private int putIndex;
/** 获取元素时的指针 */
private int takeIndex;
public ArrayExtractTuple() {
}
public ArrayExtractTuple(Object[] items, int newCapacity, int oldCapacity, int count, int putIndex, int takeIndex) {
super(newCapacity, oldCapacity, count);
this.items = items;
this.putIndex = putIndex;
this.takeIndex = takeIndex;
}
public Object[] getItems() {
return items;
}
public ArrayExtractTuple setItems(Object[] items) {
this.items = items;
return this;
}
public int getPutIndex() {
return putIndex;
}
public ArrayExtractTuple setPutIndex(int putIndex) {
this.putIndex = putIndex;
return this;
}
public int getTakeIndex() {
return takeIndex;
}
public ArrayExtractTuple setTakeIndex(int takeIndex) {
this.takeIndex = takeIndex;
return this;
}
}
我这里实现了两种类型的数组截取器:
- ArrayOldestExtracter:截取最早的数据交由Recycler处理
- ArrayLatestExtracter:截取最新的数据交由Recycler处理
2.3.2 ArrayOldestExtracter
ArrayOldestExtracter 截取最早的数据,即从takeIndex指针直接移动,算法逻辑如下:
public class ArrayOldestExtracter<E> extends ArrayAbstractExtracter<E> {
public ArrayOldestExtracter() {
super();
}
public ArrayOldestExtracter(Recycler<E> recycler) {
super(recycler);
}
@Override
protected ArrayExtractTuple doExtract(Collection<E> reclaims, ArrayExtractTuple extractTuple) {
final int newCapacity = extractTuple.getNewCapacity();
Object[] newItems = new Object[newCapacity];
//从队头回收即可 Start
final int putIndex = extractTuple.getPutIndex();
int takeIndex = extractTuple.getTakeIndex();
final int oldCapacity = extractTuple.getOldCapacity();
final Object[] items = extractTuple.getItems();
int reclaimCount = extractTuple.getCount() - newCapacity;//待回收的数量
int i = 0;//已回收的数量
int newItemsIndex = 0;//新的数组的指针
final boolean isRetrieved = recycler != null && !(recycler.equals(DEFAULT));//是否需要取回
do {
final Object item = items[takeIndex];
if (++i <= reclaimCount) {//需要回收
addCollection(reclaims, item, isRetrieved);
} else {//不需要回收
newItems[newItemsIndex] = item;
newItemsIndex++;
}
items[takeIndex] = null;//help GC
if (++takeIndex == oldCapacity) {
takeIndex = 0;
}
} while (takeIndex != putIndex);
//从队头回收即可 End
int count = 0;
final int putIdx = (count = newItemsIndex) == newCapacity ? 0 : newItemsIndex;
final ArrayExtractTuple tuple = new ArrayExtractTuple().setItems(newItems).setPutIndex(putIdx);
tuple.setCount(count);
return tuple;
}
}
这里的算法很简单,从takeIndex索引开始往后移动,多出的部分添加到集合中,剩余的部分放到新的数组中,最后返回。
2.3.3 ArrayLatestExtracter
ArrayLatestExtracter表示截取最新的数据,但是这里写算法的时候需要注意一点,就是得先截取数据,即从putIndex往前截取,数组移动的时候要从takeIndex开始,因为这样才能保证队列里元素的顺序不变。
代码如下:
public class ArrayLatestExtracter<E> extends ArrayAbstractExtracter< E> {
public ArrayLatestExtracter() {
super();
}
public ArrayLatestExtracter(Recycler<E> recycler) {
super(recycler);
}
@Override
protected ArrayExtractTuple doExtract(Collection<E> reclaims, ArrayExtractTuple extractTuple) {
final int newCapacity = extractTuple.getNewCapacity();
Object[] newItems = new Object[newCapacity];
//从队尾回收即可 Start
final int oldCapacity = extractTuple.getOldCapacity();
final int putIndex = extractTuple.getPutIndex();
int tailIndex = putIndex == 0 ? (oldCapacity - 1) : (putIndex - 1);//最后一个元素的指针
int takeIndex = extractTuple.getTakeIndex();
final Object[] items = extractTuple.getItems();
int reclaimCount = extractTuple.getCount() - newCapacity;//待回收的数量
int i = 1;//已回收的数量
int newItemsIndex = 0;//新的数组的指针
final boolean isRetrieved = recycler != null && !(recycler.equals(DEFAULT));//是否需要取回
for (int j = 0; j < extractTuple.getCount(); j++) {
if (i <= reclaimCount) {//需要回收
i++;
final Object item = items[tailIndex];
items[tailIndex] = null;//help gc
addCollection(reclaims, item, isRetrieved);//回收
if (--tailIndex < 0) {
tailIndex = oldCapacity - 1;
}
continue;
}
//剩下的元素不需要回收 Start
final Object item = items[takeIndex];
newItems[newItemsIndex] = item;
newItemsIndex++;
items[takeIndex] = null;//help gc
if (++takeIndex == oldCapacity) {
takeIndex = 0;
}
//剩下的元素不需要回收 End
}
int count = 0;
final int putIdx = (count = newItemsIndex) == newCapacity ? 0 : newItemsIndex;
final ArrayExtractTuple tuple = new ArrayExtractTuple().setItems(newItems).setPutIndex(putIdx);
tuple.setCount(count);
return tuple;
}
}
2.4 Recycler回收器
回收器的作用,就是处理多余部分的数据,其代码如下:
/**
* 回收器, 主要用于可扩缩容的队列{@link RescalableBlockingQueue}在执行缩容的时候, 多出的数据具体怎么回收的处理器
*/
public interface Recycler<E> {
/** 默认的集合大小 */
int DEFAULT_COLLECTION_SIZE = 1 << 4;
/**
* 回收处理
* @param pendings 待回收元素的集合
*/
void recycle(Collection<E> pendings);
/**
* 创建即可, 可自行创建指定的集合
* @return 集合
*/
default Collection<E> createCollection() {
return this.createCollection(DEFAULT_COLLECTION_SIZE);
}
/**
* 创建即可, 可自行创建指定的集合
* @param size 集合大小
* @return 集合
*/
Collection<E> createCollection(int size);
}
方法 recycle(Collection) 就是做回收处理的,而两个createCollection 方法是创建集合的逻辑,这样用户可以使用自己自定义的集合。
AbstractRecycler是对Recycler的createCollection(int) 的简单实现,是直接使用ArrayList作为集合:
/**
* 这里创建的集合使用的是{@link ArrayList}
*/
public abstract class AbstractRecycler<E> implements Recycler<E> {
@Override
public Collection<E> createCollection(int size) {
if (size <= 0) {
throw new RecyclerException();
}
return new ArrayList<E>(size);
}
}
默认的回收器DefaultRecycler在上述已经介绍到了,就是什么也不做。用户也可根据业务自行编写回收器。
2.4.1 线程池拒绝处理回收器
当阻塞队列在线程池中使用的时候,如果对阻塞队列缩容处理,通常的做法就是将多余非数据交给线程池的拒绝策略处理,我这里实现了一个简单这样的逻辑,ThreadPoolRejectedRecycler代码如下:
public class ThreadPoolRejectedRecycler extends AbstractRecycler<Runnable> {
private final ThreadPoolExecutor executor;
public ThreadPoolRejectedRecycler(ThreadPoolExecutor executor) {
this.executor = executor;
}
@Override
public void recycle(Collection<Runnable> pendings) {
final RejectedExecutionHandler handler = executor.getRejectedExecutionHandler();
for (Runnable runnable : pendings) {
handler.rejectedExecution(runnable, executor);
}
}
}
使用时类似如下即可:
RescalableBlockingQueue<Runnable> queue = new ArrayRescalableBlockingQueue<>(20);//阻塞队列
RejectedExecutionHandler handler = new ThreadPoolExecutor.CallerRunsPolicy();//拒绝策略
ThreadPoolExecutor executor = new ThreadPoolExecutor(2,4,30,TimeUnit.SECONDS,queue,handler);//线程池
final ThreadPoolRejectedRecycler recycler = new ThreadPoolRejectedRecycler(executor);//回收器
queue.setRecycler(recycler);//重置回收器
对于上述的可重置容量的阻塞队列,可供参考设计自己的重置容量的阻塞队列,也可直接使用,通过三大组件定制自己的功能。


评论区