




一 SynchronousQueue源码解析
通过 7、BlockingQueue之ArrayBlockingQueue源码解析 文章,我们知道阻塞队列的设计的基本思想,就是当读线程在读取数据的时候,如果队列存在元素则正常读取,当队列中没有数据的时候,则进入阻塞;而写线程也类似,当队列还有空间存放元素的时候则正常存放元素,但是当队列已满无法继续存放元素的时候,则进入阻塞状态同时唤醒被阻塞的读线程。
注意,SynchronousQueue队列并不是synchronized+队列的组合。
SynchronousQueue的设计是类似生产者、消费者的模式,SynchronousQueue本身并不会存储元素,不会像ArrayBlockingQueue队列那样可以作为容器使用,只有在消费了数据之后同一个线程才能继续往队列中存放元素,SynchronousQueue更像是一个连通生产者和消费者的管道。
1.1 SynchronousQueue示例
在介绍SynchronousQueue队列之前,我们先看一下它的简单示例:
public class SynchronousQueueTest {
public static void main(String[] args) throws Exception {
CountDownLatch shutdownLatch = new CountDownLatch(1);//关机的监视器
SynchronousQueueTask task = new SynchronousQueueTask(shutdownLatch);//操作队列的任务
task.start();//启动消费者
//向队列中发送数据 Start
int count = 4;
for (int i = 0; i < count; i++) {
task.sendReq("发送的数据-" + i);//main线程发送数据, 如果没有消费则会被阻塞
}
//向队列中发送数据 End
task.shutdown();//停机
shutdownLatch.await();
}
private static class SynchronousQueueTask implements Runnable {
/** 队列 */
final SynchronousQueue<String> queue;
/** 停机通知 */
final CountDownLatch shutdownLatch;
/** 运行状态 */
boolean running = false;
/** 引用线程 */
final Thread thread;
public SynchronousQueueTask(CountDownLatch shutdownLatch) {
this.shutdownLatch = shutdownLatch;
this.queue = new SynchronousQueue<>(true);
this.thread = new Thread(this);
thread.setDaemon(true);
}
public void start() {
running = true;
thread.start();
}
public void shutdown() {
running = false;
Thread.interrupted();
}
public void sendReq(String req) {
try {
final boolean offer = queue.offer(req, 2, TimeUnit.SECONDS);
System.out.println("是否发送成功: " + offer);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
@Override
public void run() {
while (running && !Thread.interrupted()) {
try {
final String poll = queue.poll(5, TimeUnit.SECONDS);
if (poll != null) {
System.out.println("接收到的数据: " + poll);
}
} catch (Exception e) {
e.printStackTrace();
}
}
System.out.println("线程退出(exit 0)......");
shutdownLatch.countDown();
}
}
}
运行的效果如下(每个人运行效果可能不太相同):
是否发送成功: true
接收到的数据: 发送的数据-0
接收到的数据: 发送的数据-1
是否发送成功: true
是否发送成功: true
接收到的数据: 发送的数据-2
接收到的数据: 发送的数据-3
是否发送成功: true
线程退出(exit 0)......
从示例来看,SynchronousQueue就是充当一个数据接收和获取的队列,等我们介绍细节的时候再编写一些示例,就可以看出SynchronousQueue的特性了。
1.2 SynchronousQueue简介
首先我们看一下SynchronousQueue的继承关系图:
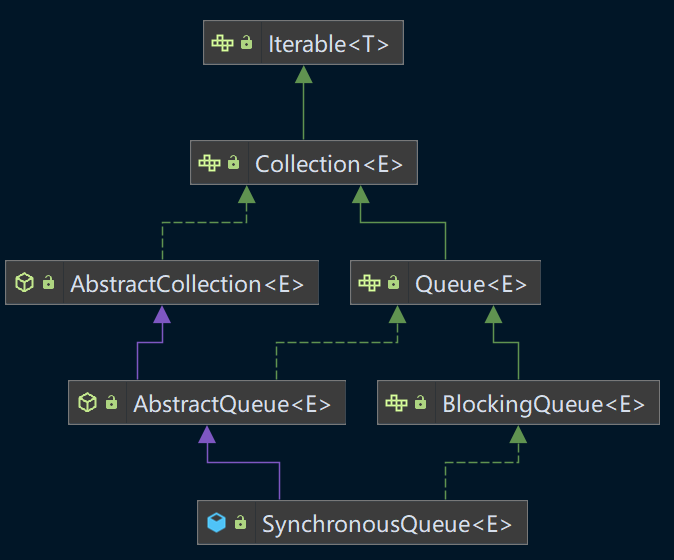
SynchronousQueue是实现了BlockingQueue接口的阻塞队列,同时也继承了抽象了AbstractQueue,而这里的Collection接口的API几乎都是没有作用的,因为SynchronousQueue在设计上本身并不存储元素。
SynchronousQueue是具有公平特性的队列,其内部维护了一个 Transferer 内部类,用以实现公平与非公平的功能。
SynchronousQueue的部分全局变量如下:
/** 有效的CPU个数, 用于控制自旋 */
static final int NCPUS = Runtime.getRuntime().availableProcessors();
/**
* 最大的自旋次数, 当有超时时间时, 如果超时时间设置的比较小, 那么如果进入阻塞的话可能还没有唤醒超时时间已经到了,
* 所以此时设置一个自旋次数, 表示在这个次数范围内一直自旋而不是进入阻塞
*/
static final int maxTimedSpins = (NCPUS < 2) ? 0 : 32;
/**
* 与上述{@link #maxTimedSpins}含义类似, 只是这个值表示当用户没有使用超时时间的函数时, 自旋的次数.
*/
static final int maxUntimedSpins = maxTimedSpins * 16;
/**
* 自旋时, 超时时间的阈值。即超时时间超过这个值的时候才会进入阻塞状态, 否则还在自旋
*/
static final long spinForTimeoutThreshold = 1000L;
/** 传输器 */
private transient volatile Transferer<E> transferer;
SynchronousQueue只有两个构造函数:
/**
* 构造函数
*/
public SynchronousQueue() {
this(false);
}
/**
* 构造函数
* @param fair 是否是公平的
*/
public SynchronousQueue(boolean fair) {
transferer = fair ? new TransferQueue<E>() : new TransferStack<E>();
}
默认的构造函数是非公平的。
1.3 Transferer传输器
Transferer在SynchronousQueue充当传输器的功能,即数据的存放和获取都是通过Transferer完成的,所以说Transferer是SynchronousQueue的核心。
Transferer只有一个抽象方法:
/**
* 传输器
*/
abstract static class Transferer<E> {
/**
* 做put或者take操作
* @param e 元素。如果为null, 则表示是消费, 即take操作; 否则是生产操作, 即put操作
* @param timed 是否需要超时
* @param nanos 超时的纳秒。{@code timed}为{@code true}时才有意义
* @return E
*/
abstract E transfer(E e, boolean timed, long nanos);
}
transfer(E, boolean, long) 是用于存储、获取元素的核心方法,通过参数E是否为空来表示是存储操作还是获取操作。Transferer有两个实现,分别表示公平的队列和非公平的队列。其两个实现类如下:

- TransferQueue:底层使用单向链表的数据结构,先进先出,属于公平队列
- TransferStack:底层使用栈的数据结构,先进可能后出,属于非公平队列
1.3.1 TransferQueue介绍
使用单向链表数据结构实现的队列,内部使用QNode作为链表的节点,QNode持有的字段有:
/** 队列中下一个元素 */
volatile QNode next;
/** 元素 */
volatile Object item;
/** 控制唤醒和阻塞操作 */
volatile Thread waiter;
/** 模式, 这里表示是否是生产者 */
final boolean isData;
其中item表示元素,如果是插入操作的话就是元素要插入的内容,如果是获取操作的话,此字段为空。QNode的构造函数只有一个,需要传递item和isData:
/**
* 构造函数
* @param item 元素项
* @param isData isData
*/
QNode(Object item, boolean isData) {
this.item = item;
this.isData = isData;
}
TransferQueue持有的字段有队头和队尾的指针:
/** 队头 */
transient volatile QNode head;
/** 队尾 */
transient volatile QNode tail;
在构造TransferQueue对象的时候,初始状态会有一个虚节点,头指针和尾指针都指向这个虚节点:
/**
* 构造函数。这里会初始化队头和队尾, 此时队头和队尾都指向同一个节点
*/
TransferQueue() {
QNode h = new QNode(null, false);
head = h;
tail = h;
}
其他的一些方法我们后面再详细解析。
1.3.2 TransferStack介绍
TransferStack属于非公平队列的实现,底层使用栈的数据结构。内部维护了SNode作为栈中节点存储,SNode维护的字段有:
/** 下一个元素 */
volatile SNode next;
/** 与this匹配的节点 */
volatile SNode match;
/** 阻塞/唤醒的线程 */
volatile Thread waiter;
/** 数据 */
Object item;
/** 模式 */
int mode;
SNode也只有一个构造函数,需要传递的参数是item:
/**
* 构造函数
* @param item 数据
*/
SNode(Object item) {
this.item = item;
}
而在TransferStack对象中有SNode.mode的模式值以及栈顶的指针:
/** {@link SNode}的模式, 表示消费模式 */
static final int REQUEST = 0;
/** {@link SNode}的模式, 表示生产模式 */
static final int DATA = 1;
/** 判断是否有元素填充的, 二进制为 00000000 00000000 00000000 00000011 */
static final int FULFILLING = 2;
/** 栈顶的指针 */
volatile SNode head;
而其他的方法我们在后面详细介绍。
上述简单介绍了TransferQueue和TransferStack,主要介绍了全局变量以及对应的构造函数,下面我们具体分析怎么存储、怎么获取元素的。
1.4 插入元素
插入元素的方法有:
| 方法 | 描述 |
|---|---|
| boolean add(E) | 添加元素, 调用offer(E), 如果添加失败则抛出异常 |
| boolean offer(E) | 添加元素, 同一个线程如果多次添加,则只能添加一次,在未消费之前同一个线程继续添加数据的话,会return false |
| boolean offer(E, long, TimeUnit) | 添加元素, 与offer(E)一样,只是会阻塞对应的时间 |
| void put(E) | 添加元素, 与offer(E, long, TimeUnit)一样,这里阻塞没有超时时间,是一致阻塞 |
add(E)方法是AbstractQueue的,这里不做介绍了。
offer(E)、offer(E, long, TimeUnit)、put(E) 代码分别如下:
/**
* 添加元素到队列, 等待其他线程来获取
* 调用这个方法需要注意, 如果是公平队列{@link TransferQueue}的话, 消费者可能消费不到数据, 会导致
* 生产者生产一条数据, 消费者可能并不一定能够消费。
* 所以应当避免调用该方法
* @param e 元素
*/
public boolean offer(E e) {
if (e == null) throw new NullPointerException();
return transferer.transfer(e, true, 0) != null;
}
/**
* 添加元素到队列, 等待其他线程来获取
* @param e 元素
* @param timeout 超时时间
* @param unit 时间单位
* @throws InterruptedException 异常
*/
public boolean offer(E e, long timeout, TimeUnit unit) throws InterruptedException {
if (e == null) throw new NullPointerException();
if (transferer.transfer(e, true, unit.toNanos(timeout)) != null)//存放元素
return true;
if (!Thread.interrupted())
return false;
throw new InterruptedException();
}
/**
* 添加元素到队列, 等待其他线程来获取
* @param e 元素
* @throws InterruptedException 异常
*/
public void put(E e) throws InterruptedException {
//非空校验 Start
if (e == null) throw new NullPointerException();
//非空校验 End
if (transferer.transfer(e, false, 0) == null) {//存放元素
Thread.interrupted();
throw new InterruptedException();
}
}
三个方法都会调用transferer.transfer(E, boolean, long) 方法,我们稍后介绍这个方法。
1.5 获取元素
获取元素的方法有:
| 方法 | 描述 |
|---|---|
| E peek() | 不支持操作。 |
| E poll() | 获取队列头元素,如果队列没有元素则直接返回null |
| E poll(long, TimeUnit) | 获取队列头元素,如果队列没有元素则阻塞指定时间 |
| E take() | 与poll(long, TimeUnit)类似,只是没有超时时间的死等 |
peek()、poll()、poll(long, TimeUnit)、take() 代码如下:
/**
* 不支持的操作
* @return null
*/
public E peek() {
return null;
}
/**
* 消费者获取元素
* @return 获取到的元素
*/
public E poll() {
return transferer.transfer(null, true, 0);
}
/**
* 消费者获取元素
* @param timeout 超时时间
* @param unit 时间单位
* @return 元素
* @throws InterruptedException 异常
*/
public E poll(long timeout, TimeUnit unit) throws InterruptedException {
E e = transferer.transfer(null, true, unit.toNanos(timeout));
if (e != null || !Thread.interrupted())
return e;
throw new InterruptedException();
}
/**
* 添加元素到队列, 等待其他线程来获取
* @param e 元素
* @throws InterruptedException 异常
*/
public void put(E e) throws InterruptedException {
//非空校验 Start
if (e == null) throw new NullPointerException();
//非空校验 End
if (transferer.transfer(e, false, 0) == null) {//存放元素
Thread.interrupted();
throw new InterruptedException();
}
}
同样,这几个方法都会调用transferer.transfer(E, boolean, long) 方法,只是这里传递的参数E是null。下面我们具体分析这个方法的处理逻辑。
1.6 transfer-公平队列
通过上文我们知道,TransferQueue是公平队列的实现,那么我们分析TransferQueue.transfer(E, boolean, long) 的方法:
/**
* 做put或者take操作
* @param e 元素。如果为null, 则表示是消费, 即take操作; 否则是生产操作, 即put操作
* @param timed 是否需要超时
* @param nanos 超时的纳秒。{@code timed}为{@code true}时才有意义
* @return E
*/
@SuppressWarnings("unchecked")
E transfer(E e, boolean timed, long nanos) {
QNode s = null;//构造/或者重复使用的节点
boolean isData = (e != null);//是否是生产者
//无限循环, 主体逻辑 Start
for (; ; ) {
QNode t = tail;//队尾
QNode h = head;//队头
//未初始化完成, 自旋, 直到条件不满足 Start
if (t == null || h == null)
continue;
//未初始化完成, 自旋, 直到条件不满足 End
if (h == t || t.isData == isData) {//空队列或相同的模式
QNode tn = t.next;
//有线程变更了tail节点 Start
if (t != tail)
continue;
//有线程变更了tail节点 End
//tail节点的next节点有元素, 此时t节点不应该是tail节点, 而tn才是tail节点 Start
if (tn != null) {
advanceTail(t, tn);
continue;
}
//tail节点的next节点有元素, 此时t节点不应该是tail节点, 而tn才是tail节点 End
//不等待 Start
if (timed && nanos <= 0)
return null;
//不等待 End
//构造节点 Start
if (s == null)
s = new QNode(e, isData);
//构造节点 End
//CAS更新tail节点的next元素为s对象 Start
if (!t.casNext(null, s))
continue;
//CAS更新tail节点的next元素为s对象 End
advanceTail(t, s);//将tail节点也更新为s对象
Object x = awaitFulfill(s, e, timed, nanos);//阻塞(这个x是s对象中的item)
//下面是做一些清理工作了 Start
//如果x和s相同的话, 那么证明调用了s.tryCancel()方法, 所以是需要取消的 Start
if (x == s) {
clean(t, s);//清除
return null;
}
//如果x和s相同的话, 那么证明调用了s.tryCancel()方法, 所以是需要取消的 End
//尚未取消连接 Start
if (!s.isOffList()) {
advanceHead(t, s);//将head节点更新成s节点
//如果是生产者, 则将s.item指向s对象 Start
if (x != null)
s.item = s;
//如果是生产者, 则将s.item指向s对象 End
s.waiter = null;
}
//尚未取消连接 End
//下面是做一些清理工作了 End
return (x != null) ? (E) x : e;
} else {//不同的模式
QNode m = h.next;
//有线程变更过队头或队尾 Start
if (t != tail || m == null || h != head)
continue;
//有线程变更过队头或队尾 End
Object x = m.item;
if (isData == (x != null) || //m已经被填充
x == m || //m是取消的
!m.casItem(x, e)) { //CAS item为e
advanceHead(h, m);//更新head节点为m
continue;
}
advanceHead(h, m); //成功填充
LockSupport.unpark(m.waiter);//阻塞当前线程
return (x != null) ? (E) x : e;
}
}
//无限循环, 主体逻辑 End
}
其中的一些CAS方法:
- advanceTail():CAS操作tail指针
- casNext():CAS操作QNode.next指针
- advanceHead():CAS操作head指针
- casItem():CAS操作QNode.item对象
这些方法就不做详细介绍了,就是利用Unsafe进行CAS操作而已,有兴趣的可自行阅读。
transfer(E, boolean, long) 方法看似很复杂,其实主体逻辑还是很清晰的。如果只有生产没有消费或只有消费没有生产或生产速度超过了消费速度都会进入awaitFulfill(QNode, E, boolean, long) 方法,在该方法中主要的逻辑就是阻塞:
/**
* 自旋/阻塞, 直到节点被填充
* @param s 节点
* @param e 用户的数据
* @param timed 是否超时
* @param nanos 超时的纳秒
* @return Object
*/
Object awaitFulfill(QNode s, E e, boolean timed, long nanos) {
final long deadline = timed ? System.nanoTime() + nanos : 0L;//超时的时间节点
Thread w = Thread.currentThread();//当前线程
int spins = ((head.next == s) ? (timed ? maxTimedSpins : maxUntimedSpins) : 0);//自旋次数
//无限循环, 主体逻辑 Start
for (; ; ) {
//中断 Start
if (w.isInterrupted())
s.tryCancel(e);
//中断 End
Object x = s.item;//节点项
//节点项与当前存储的数据不同, 则直接返回节点项 Start
if (x != e)
return x;
//节点项与当前存储的数据不同, 则直接返回节点项 End
//需要超时阻断 Start
if (timed) {
nanos = deadline - System.nanoTime();
if (nanos <= 0L) {//超时
s.tryCancel(e);//取消
continue;
}
}
//需要超时阻断 End
if (spins > 0)
--spins;
else if (s.waiter == null)
s.waiter = w;
else if (!timed)//不需要超时
LockSupport.park(this);//阻塞
else if (nanos > spinForTimeoutThreshold)//超时时间超过阈值
LockSupport.parkNanos(this, nanos);//阻塞
}
//无限循环, 主体逻辑 End
}
结合这两个方法,不管是插入元素还是获取元素调用的都是同一个方法,所以我们对插入元素和获取元素同时分析。
我们以这样一个示例:现在有3个线程同时插入元素(无等待时间的插入,即调用put(E) 方法),插入完元素后等待几秒再一个启动消费者消费同一个队列中的元素。
利用上述的示例,来详细分析代码的原理。
1.6.1 插入元素分解
- 当构造了一个SynchronousQueue队列之后,此时的队列如下所示:

此时head指针和tail指针都指向一个初始创建的QNode节点,我们称为虚节点,虚节点的其他字段都是空的,而isData是为false的。
- 第一个线程调用了put(E) 方法后,进入了for ( ; ; ) 循环体,此时判断 head(h) == tail(t) 是为true的,所以进入第一个if(h == t || t.isData == isData){} 代码块,那么此时继续走,发现节点 “s” 是空的,所以构造了一个 “s” 节点,接着将tail(t)指针的next字段指向了这个 “s” 节点(代码为 t.casNext(null, s)), 此时队列如下:
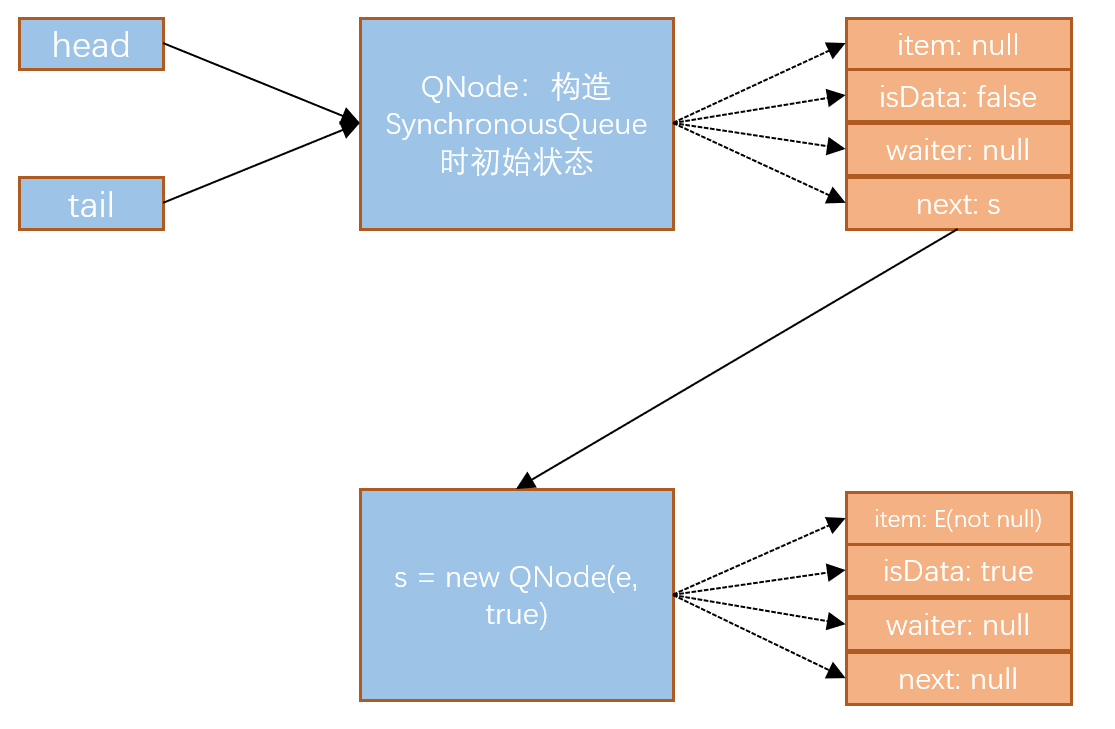
到这里,此时的tail.next 即为刚刚创建的节点 "s"了。
- 代码继续往下走,即走到了advanceTail(t, s) 代码,即将tail节点的指针指向了节点 “s” 了。那么队列图如下:
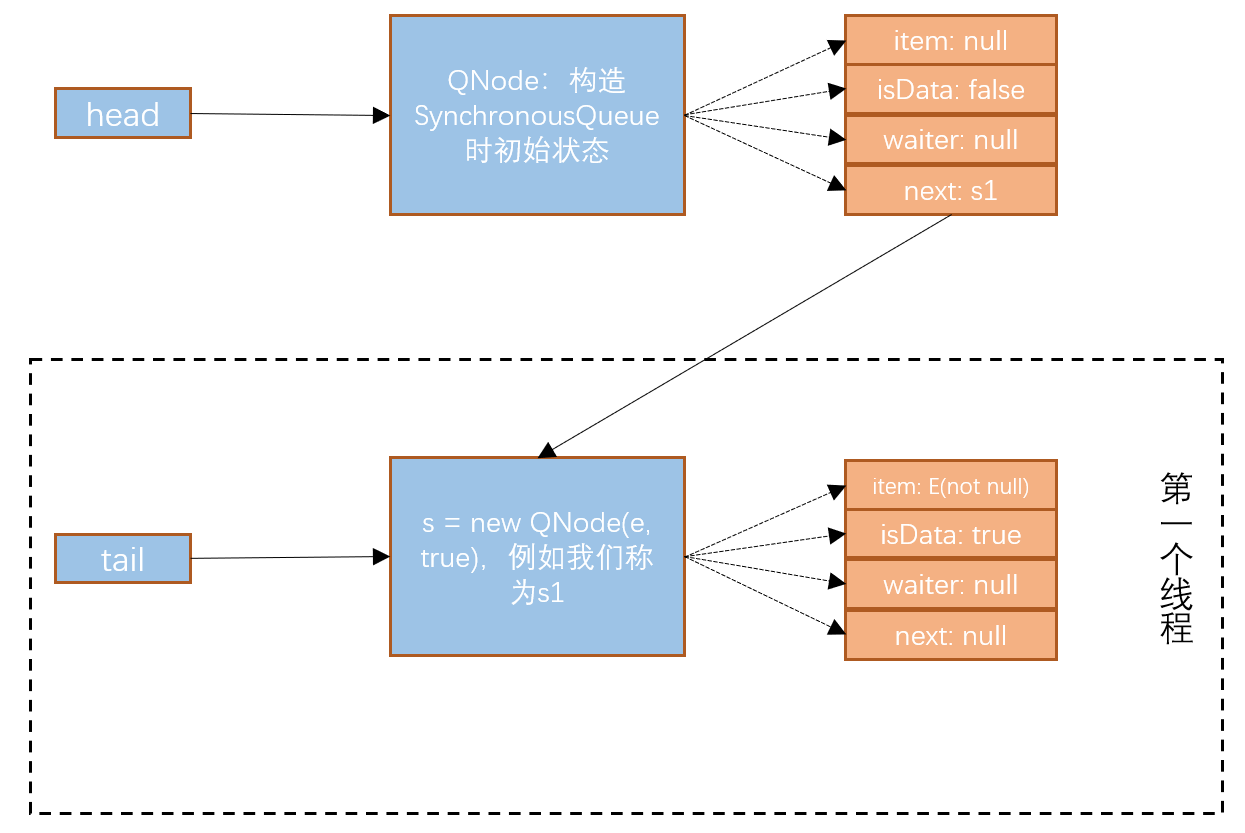
此时SynchronousQueue的tail指针指向了节点 “s”,即插入节点的时候是从队列尾部插入的。
-
接下来就是进入 awaitFulfill(s, e, timed, nacos) 方法了。在该方法里面,进入for( ; ; ) 循环体,此时 s.item(x) 其实就是 e,即不会进入 if (x != e) {} 代码块。那么自旋完成之后还是没有消费者则进入 else if (!timed) {} 代码块后当前线程被阻塞。到这里第一个线程被阻塞了
-
接下来就是第二个线程插入操作,与上述流程一样,但是这里不是空队列,而是 tail(t).isData = isData 条件满足了,此时队列如下:
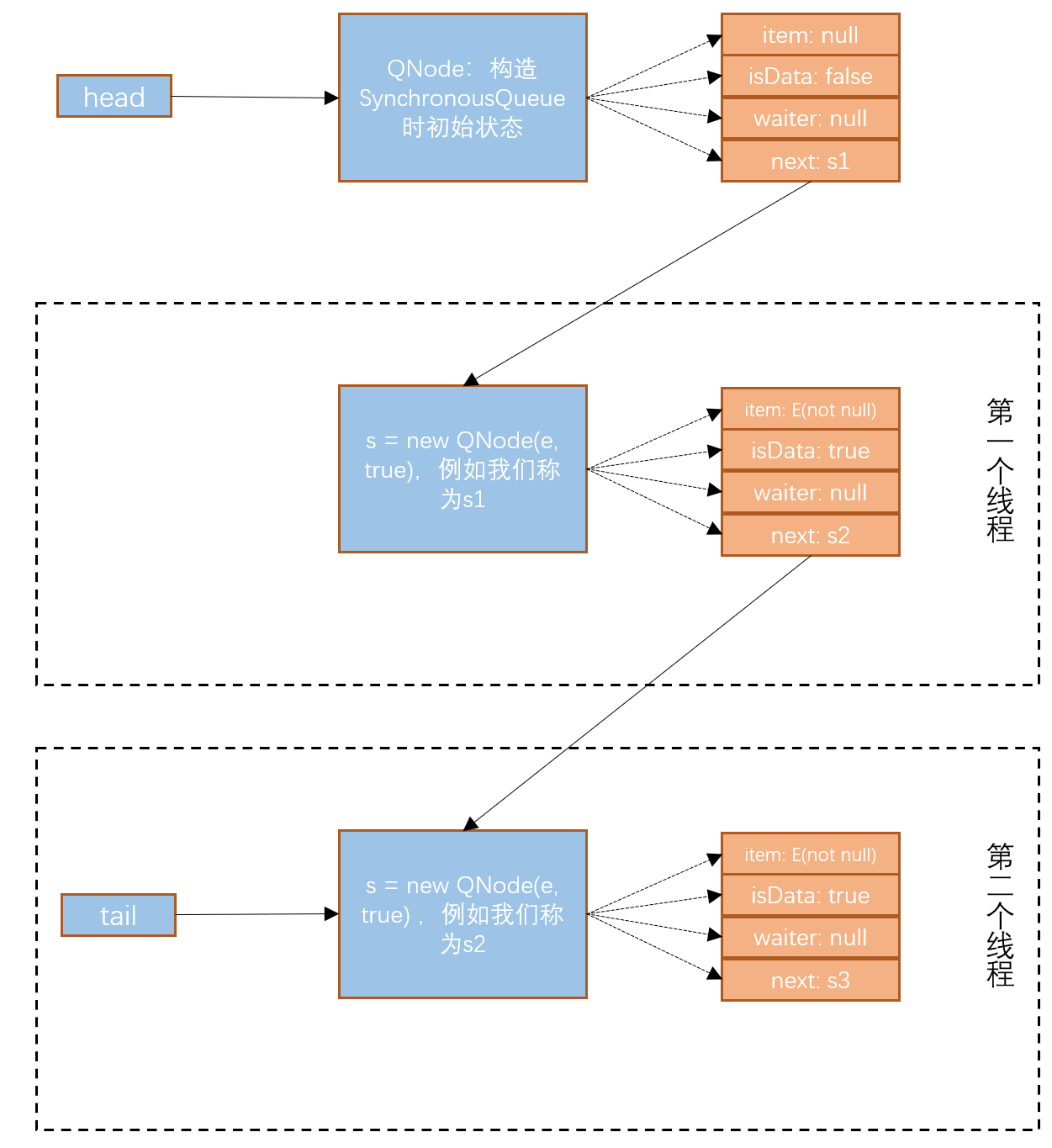
第二个线程将数据插入到队尾,tail的指针指向了第二个线程的QNode节点,并且第一个线程的next指针指向了第二个线程创建的QNode对象。同时,第二个线程被阻塞。通过上图我们就很清晰的理解这个结构队列了。
- 第三个线程与第二个线程几乎一模一样,此时队列如下:
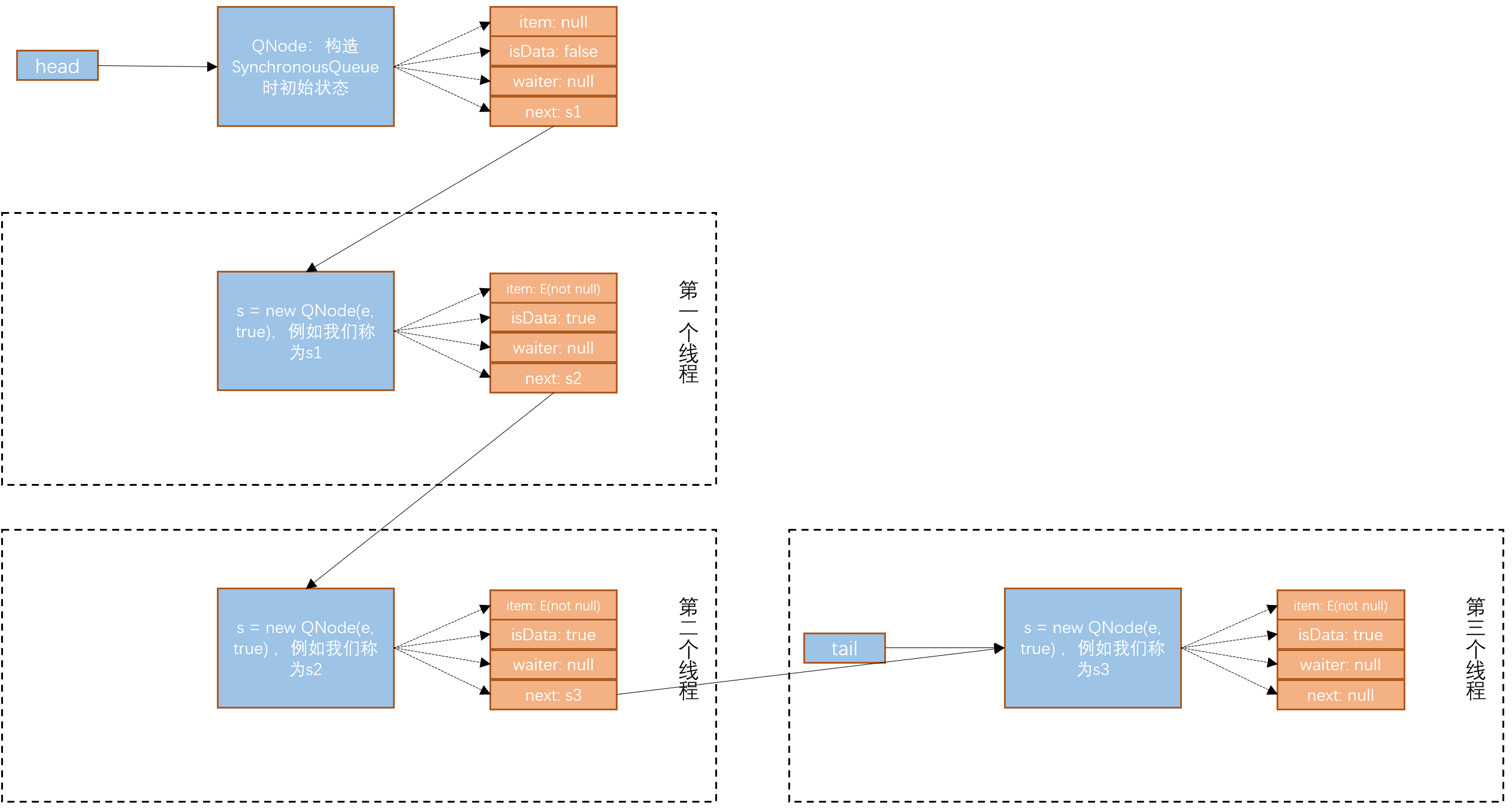
队列如上图所示,tail指针指向了s3,s2.next 指针指向了 s3。此时三个添加的线程都会被阻塞。接下来我们看获取元素的流程。
1.6.2 获取元素分解
- 线程进入 take() 方法后,进入 for( ;; ) 循环体,此时的isData = (e != null) 是为false的,同时tail != head,所以不会进入第一个if(h == t || t.isData == isData) {} 代码块,那么就进入了 else {} 代码块。此时 Object m = h.next,即s1(QNode),所以Object x = m.item(s1.e),即不会为空,并且x != m,那么就CAS更新m对象的item字段,更新为e,也就是更新为null。此时队列如下:

注意,此时的第一个线程创建的节点 “s” 对象的item就更新成当前获取线程的 E了,也就是更新成 null了。如上图所示。
- 通常在获取线程没有并发的情况下,CAS更新成功,也就是不会进入 if (isData == (x != null) || x == m || !m.casItem(x, e)) {} 代码块。那么继续往下走,就会走到 advanceHead(h, m) 代码块,将head指针更新为m,也就是s1(QNode),同时将原head指针的next元素指向本身。此时的队列如下:
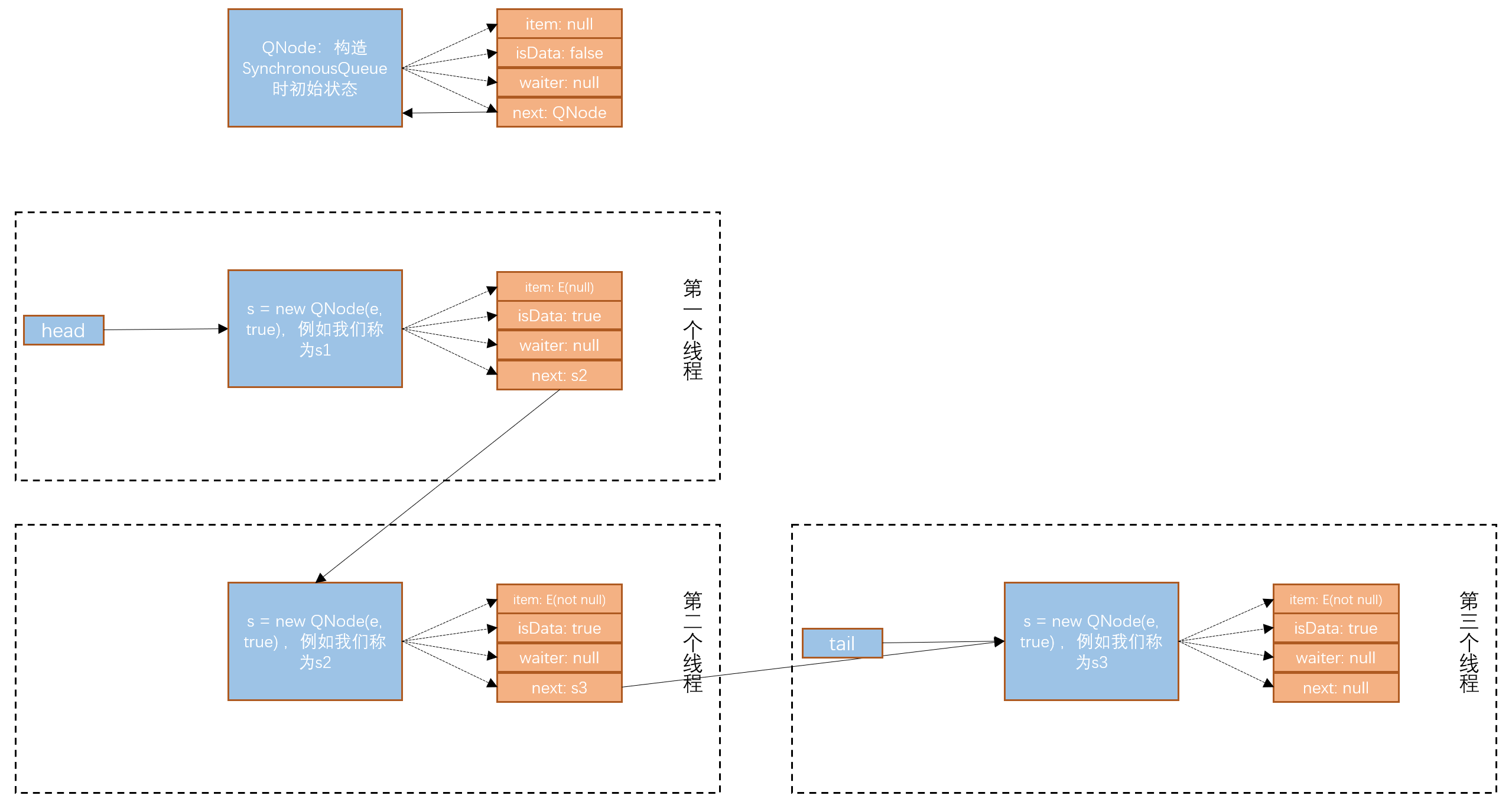
此时最顶上的节点就自引用了,GC不会回收,而是手动回收,head指针也指向了s1节点。此时会唤醒第一个线程,并且执行return操作,将上一步获取到的对象x(原s1.item)返回给用户了。
-
此时第一个线程被唤醒,即在 awaitFulfill(QNode, E, boolean, long) 方法中的 else if (!timed) {} 代码块中被唤醒,这里的QNode是s1,但是s1.item经过上述步骤已经变为null了。第一个线程继续执行循环,Objext x = s.item(null),此时x 已经和第一个线程的e(第一个线程的e就是用户塞入的数据)已经不相等了,就会return x, 也就是return null了。那么就返回到第一个线程的transfer(E, boolean, long) 方法中的 Objext x = awaitFulfill(QNode, E, boolean, long) 那一行代码(之前在这被阻塞) 。接下来就是一些清理工作了,而清理工作其实很简单,可自行阅读源码。清理完成之后第一个线程的生命周期就已经结束了。
-
接下来消费线程继续执行take() 操作,步骤同上。不做重复介绍了。
到这里对于公平队列的解析已经完毕了,在公平队列中,底层使用链表的数据结构,使用尾插法实现插入元素逻辑,而从队头往队尾读的方式拿取元素,实现了先来后到的公平的含义。
1.7 transfer-非公平队列
非公平队列使用的是TransferStack实现的,TransferStack.transfer(E, boolean, long) 代码如下:
/**
* 做put或者take操作
* @param e 元素。如果为null, 则表示是消费, 即take操作; 否则是生产操作, 即put操作
* @param timed 是否需要超时
* @param nanos 超时的纳秒。{@code timed}为{@code true}时才有意义
* @return E
*/
@SuppressWarnings("unchecked")
E transfer(E e, boolean timed, long nanos) {
SNode s = null;//节点
int mode = (e == null) ? REQUEST : DATA;//模式
//无限循环, 主体逻辑 Start
for (; ; ) {
SNode h = head;//栈顶
if (h == null || h.mode == mode) {//空的或者相同模式
if (timed && nanos <= 0) {//不用等待
if (h != null && h.isCancelled())
casHead(h, h.next);
else
return null;
} else if (casHead(h, s = snode(s, e, h, mode))) {//CAS更新head节点为s节点
SNode m = awaitFulfill(s, timed, nanos);//阻塞
//取消了 Start
if (m == s) {
clean(s);
return null;
}
//取消了 End
if ((h = head) != null && h.next == s)
casHead(h, s.next);
return (E) ((mode == REQUEST) ? m.item : s.item);
}
} else if (!isFulfilling(h.mode)) {//是消费模式
if (h.isCancelled())//已经取消了
casHead(h, h.next);
else if (casHead(h, s = snode(s, e, h, FULFILLING | mode))) {//更新head节点为s
for (; ; ) {//匹配
//没有下一个节点 Start
SNode m = s.next;
if (m == null) {
casHead(s, null);
s = null;
break;
}
//没有下一个节点 End
SNode mn = m.next;
if (m.tryMatch(s)) {//尝试匹配
casHead(s, mn);//弹出
return (E) ((mode == REQUEST) ? m.item : s.item);
} else //没有匹配到
s.casNext(m, mn); // help unlink
}
}
} else {
SNode m = h.next;
if (m == null)
casHead(h, null);
else {
SNode mn = m.next;
if (m.tryMatch(h))
casHead(h, mn);
else
h.casNext(m, mn);
}
}
}
//无限循环, 主体逻辑 End
}
非公平队列的逻辑与公平队列的逻辑上其实是一样的,只是数据结构不太一样。阻塞方法都是awaitFulfill(SNode, boolean, long) :
/**
* 自旋或阻塞
* @param s 节点
* @param timed 是否超时
* @param nanos 超时纳秒
* @return SNode
*/
SNode awaitFulfill(SNode s, boolean timed, long nanos) {
final long deadline = timed ? System.nanoTime() + nanos : 0L;//超时时间
Thread w = Thread.currentThread();//当前线程
int spins = (shouldSpin(s) ? (timed ? maxTimedSpins : maxUntimedSpins) : 0);//自旋次数
//无限循环, 主体逻辑 Start
for (; ; ) {
//中断 Start
if (w.isInterrupted())
s.tryCancel();
//中断 End
SNode m = s.match;
if (m != null)
return m;
if (timed) {
nanos = deadline - System.nanoTime();
if (nanos <= 0L) {
s.tryCancel();
continue;
}
}
if (spins > 0)
spins = shouldSpin(s) ? (spins - 1) : 0;
else if (s.waiter == null)
s.waiter = w;
else if (!timed)
LockSupport.park(this);
else if (nanos > spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanos);
}
//无限循环, 主体逻辑 End
}
这里就不做图形解析了,说白了,使用栈的结构,即先插入的元素会后读取,使用一个栈顶的指针head,插入元素放入head.next指针中,读取元素从栈顶开始读取,即先插入的后读取,后插入的先读取的概念,实现了非公平的含义。具体可自行画图解析。
1.8 SynchronousQueue总结
到这里我们已经分析了SynchronousQueue的主体原理了,而其他的一些辅助的方法,可自行阅读源码,都是很简单的。下面我们对SynchronousQueue做一个总结:
- SynchronousQueue是一个不存储元素的队列,不可将其作为容器使用
- 没有互斥量,使用无锁机制,插入和读取操作使用CAS控制
- 由于是不存储元素的队列,一些方法是不可用的,如peek()、size()、toArray()等
- 存在公平性的特质,公平队列使用链表的数据结构,先来先出;非公平队列使用栈的数据结构,先来后出
- SynchronousQueue如果消费不及时的话,就会存在如下问题:
- 写线程被阻塞,如果消费不及时,又存在大量的写的话,就会有大量的写线程被阻塞(一般队列都会存在这种问题)
- 如果插入元素调用的是offer(E)或offer(E, long, TimeUnit)的方法的话,如果消费不及时,就会存在丢失元素的可能,所以使用该方法的时候一定要判断结果boolean是否为true,不为true的话执行重试或者一些自定义的逻辑
- 使用无锁技术,理论上性能要高于有锁的队列的
经过文章 7、BlockingQueue之ArrayBlockingQueue源码解析 和当前文档的分析,我们已经介绍了BlockingQueue的主要设计思想以及两个代表性的队列了,而对于Java中其他的阻塞队列,一些是数据结构不同,一些是使用场景不同,但是万变不离其宗,整体设计不会变更,所以如果对其他队列感兴趣的话,可自行阅读源码。


评论区